Residual in plain english means
adjective: residual
remaining after the greater part or quantity has gone.
SQLServer residual predicates also mean the same thing.If you have more than 1 predicate in a query,SQLServer filters most of the data using one predicate and uses the second predicate to filter out each row in left over result set …
Lets do a demo to understand more on this
--create a table and fill it with 100 row
create table #test2
(
id int,
name varchar(10)
)
insert into #test2
select n ,cast(n as varchar(4))+'a'
from numbers
where n<=100
Let’s also create an index on this table
create index nci_nmbr_nm on #test2(id,name)
Now let’s run below query
select * from #test2 where id=99 and name='99a'
Below is the execution plan of that query
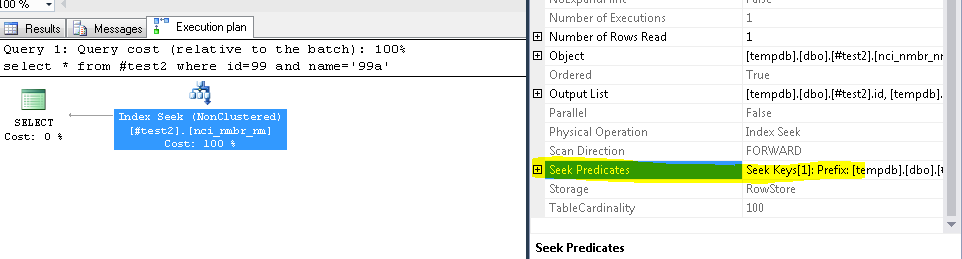
As you can observe,we could see only one predicate
Now let’s run below query
select * from #test2 where id>=99 and name='99a'
Below is the execution plan of the query
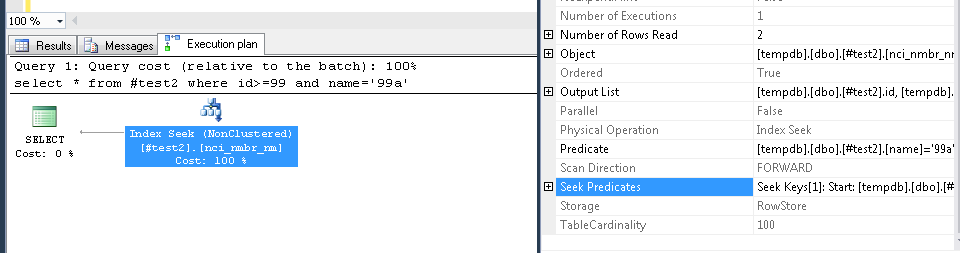
As you can see,we have to predicates
- Predicate
- seek predicate
What happened here ..? how to infer this predicates..
SQLServer first did a seek using id>=99.The result set obtained from first predicate is again filtered out using name=99a
Here 99a is called residual predicate
The impact of residual predicate can be very huge ,if the first predicate is not selective enough.In our case,resiudal predicate had only one row.Imagine the first predicate(>=99) matched some 1 lakh rows,Now residual predicate(in our case 99a) had to evaluated against these 1 lakh rows.That would be cubersome and index we have is not worthy.
That’s pretty much about residual predicates .
References:
A new superpower for SQL query tuners – Number of Rows Read