Rebinds and Rewinds are one of the important properties to look for while tuning a query,Lets populate some sample data to understand more on what these mean
drop table if exists #t1;--this works from 2016 sp1,if you are not using this,use old syntax
drop table if exists #t2;
create table #t1
(id int
)
create table #t2
(id int
)
insert into #t1
select top 100 * from numbers
order by n
insert into #t2
select top 100 * from numbers where n>20
order by n
update t1
set t1.id=(select top 1 id from #t2 t2 Order By newid())
from #t1 t1
the above query tries to update t1 with a random value from t2(which won’t work though,we will see in a bit ,why ?)
below is the execution plan of above update
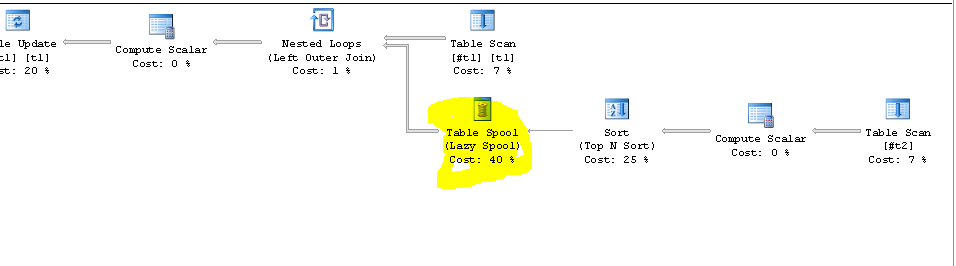
As you can see,SQL tried to store data into a spool.If we check the properties of that spool,we can further see
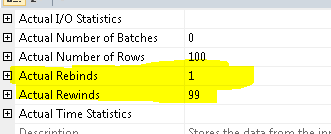
SQL did 99 Rewinds and only rebind,which means SQL scanned t2 only once and used that same table
Now lets see execution plan for below correlated update
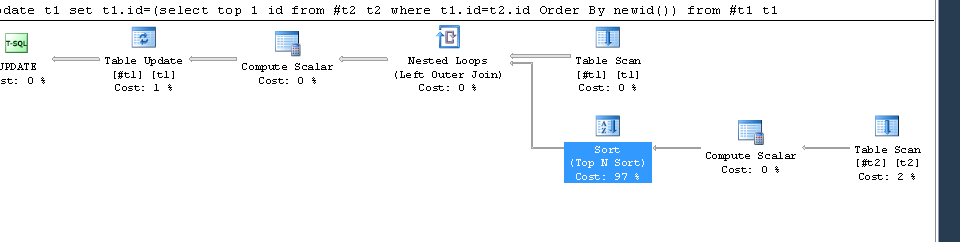
When looking at properties of TOPNSORT, we can see
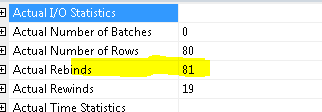
In this case,SQL did 81 rebinds (81 because of 81 mtaching rows).so for each matching value,SQL has to go to main table and get the data
So in case of rewind ,SQL server ,fetches the data only once and uses the same data .Incase of Rebind,SQL has to discard the data and start again with new set of values
Hope this helps you in knowing these properties ,when you look at the plan
References :
Rebind and Rewind in Execution Plans
Understanding Query Plans